PRCV & DICTA 2022联合论坛
中国和澳大利亚的学术界皆在国际上具有广泛的影响力。为了加强中澳两国的学术交流和学术联系,PRCV 2022和DICTA 2022会议将举办联合论坛。联合论坛将从这两个会议中,各邀请优秀论文的作者,在联合论坛上口头报告论文中的成果。联合论坛将面向这两个会议的参会者,分别在PRCV 2022和DICTA 2022上采用线上线下结合的方式举办,以促进两个会议参会者之间的交流。
DICTA (International Conference on Digital Image Computing: Techniques and Applications) 由澳大利亚模式识别学会(Australian Pattern Recognition Society)于1991创立,是澳大利亚计算机视觉、图像处理、模式识别和相关领域的主要学术会议。DICTA 2022将于2022年11月30日至12月2日在澳大利亚悉尼举办。DICTA 2022会议网址 http://dicta2022.dictaconference.org/。
论坛语言:英语
联合论坛委员会
于仕琪、张兆翔、阮邦志、韩军伟、Min Xu、Du Huynh、Wei Xiang
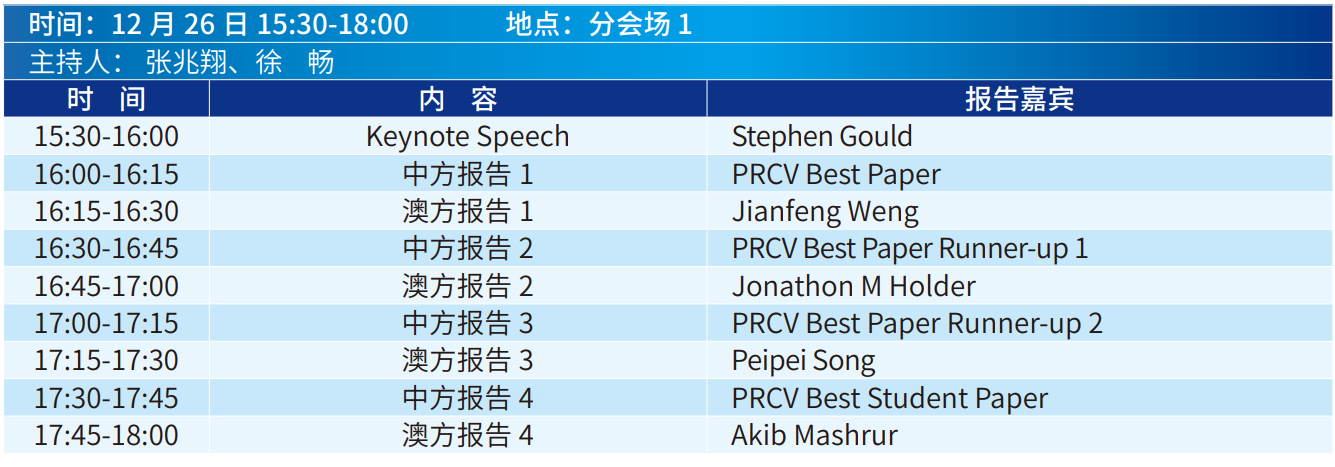
论坛日程
论坛嘉宾

Stephen Gould 报告嘉宾
Professor, Australian National University
嘉宾简介:Stephen Gould is a Professor of Computer Science at the Australian National University (ANU). He is also an Australian Research Council (ARC) Future Fellow and Amazon Scholar. He is a former ARC Postdoctoral Fellow, Microsoft Faculty Fellow, Contributed Researcher at Data61, Principal Research Scientist at Amazon Inc, and Director of the ARC Centre of Excellence in Robotic Vision. Stephen received his BSc degree in mathematics and computer science and BE degree in electrical engineering from the University of Sydney in 1994 and 1996, respectively. He received his MS degree in electrical engineering from Stanford University in 1998. He then worked in industry for several years where he co-founded Sensory Networks, which later sold to Intel in 2013. In 2005 he returned to Stanford University and was awarded his PhD degree in 2010. In November 2010, he moved back to Australia to take up a faculty position at the ANU. Stephen has broad interests in the areas of computer and robotic vision, machine learning, deep learning, structured prediction, and optimization. He teaches courses on advanced machine learning, research methods in computer science, and the craft of computing. His main research focus is on automatic semantic, dynamic and geometric understanding of images and videos.
报告题目:Deep Declarative Networks with Application to Optimal Transport
报告摘要:Deep declarative networks (DDNs) are a new class of deep learning model that allows optimization problems to be embedded within end-to-end learnable pipelines. In this talk I will introduce DDNs and related concepts---implicit layers and differentiable optimization---and give some formal results for second-order differentiable problems. I will then present a concrete example of a DDN layer in the case of optimal transport, and show that by applying the DDN results we can obtain significant memory and speed improvements over unrolling Sinkhorn iterates, as would be required in traditional deep learning models Limitations of DDNs and open questions will also be discussed.
Jianfeng Weng 报告嘉宾
PhD student, University of Sydney
报告题目:Robust Knowledge Adaptation for Federated Unsupervised Person ReID
报告摘要:Person Re-identification (ReID) has been extensively studied in recent years due to the increasing demand in public security. However, collecting and dealing with sensitive personal data raises privacy concerns. Therefore, federated learning has been explored for Person ReID, which aims to share minimal sensitive data between different parties (clients). However, existing federated learning based person ReID methods generally rely on laborious and time-consuming data annotations and it is difficult to guarantee cross-domain consistency. Thus, in this work, a federated unsupervised cluster-contrastive (FedUCC) learning method is proposed for Person ReID. FedUCC introduces a three-stage modelling strategy following a coarse-to-fine manner. In detail, generic knowledge, specialized knowledge and patch knowledge are discovered using a deep neural network. This enables the sharing of mutual knowledge among clients while retaining local domain-specific knowledge based on the kinds of network layers and their parameters. Comprehensive experiments on 8 public benchmark datasets demonstrate the state-of-the-art performance of our proposed method.
Jonathon M Holder 报告嘉宾
PhD student, Griffith University
报告题目:Machine Vision Approach for Slipper Lobster Weight Estimation
报告摘要:Computer vision techniques have been successfully applied across a large number of industries for a variety of purposes. In this work we extend the capabilities of computer vision to slipper lobster weight estimation. Our proposed method combines machine learning and traditional computer vision techniques to first detect slipper lobsters and their eyes. An algorithm to determine which eyes belong to which slipper lobster and estimate the weight from the distance between the eyes is then developed. The proposed method correctly identifies 86% of lobster eye pairs and estimates weight with a mean error of 4.78g. Our weight estimation method achieves high accuracy and has the potential to be implemented within aquaculture operations in the future.
Peipei Song 报告嘉宾
PhD student, Australian National University
报告题目:Stereo Saliency Detection by Modeling Concatenation Cost Volume Feature
报告摘要:RGB-D image pair based salient object detection models aim to localize the salient objects in an RGB image with extra depth information about the scene provided to guide the detection process. The conventional practice for this task involves explicitly using depth as input to achieve multi-modal learning. In this paper, we observe two main issues within existing RGB-D saliency detection frameworks. Firstly, we claim that it is better to define depth as extra prior information instead of as a part of the input for RGB-D saliency detection, as we can directly perform saliency detection based only on the appearance information from the RGB image, while we cannot perform saliency detection given only the depth data. Secondly, there exists a huge domain gap in terms of the source of depth between different benchmark testing datasets, e.g., depth from Kinect and stereo cameras. In this paper, we focus on the variant of stereo image pair based saliency detection, where the depth is implicitly encoded in the stereo image pair for effective RGB-D saliency detection. Experimental results illustrate the effectiveness of our solution.
Akib Mashrur 报告嘉宾
PhD student, Deakin University
报告题目:Semantic multi-modal reprojection for robust visual question answering
报告摘要:Despite recent progress in the development of vision-language models in accurate visual question answering (VQA), the robustness of these models is still quite limited in the presence of out-of-distribution datasets that include unanswerable questions. In our work, we first implement a randomised VQA dataset with unanswerable questions to test the robustness of a state-of-the-art VQA model. The dataset combines visual input with randomised questions from the VQA v2 dataset to test the sensitivity of the model predictions. We establish that even on unanswerable questions that are not relevant to the visual clues, a state-of-the-art VQA model either fails to predict the "unknown" answer or gives an inaccurate answer with a high softmax score. To alleviate this issue without needing to retrain the large backbone models, we propose a technique called Cross Modal Augmentation (CMA), a multi-modal semantic augmentation during test time only. CMA reprojects the visual and textual inputs into multiple copies, while maintaining semantic information. These multiple instances, with similar semantics, are then fed to the same model and the predictions are combined to achieve a more robust output from the model. We demonstrate that using this model-agnostic technique enables the VQA model to provide more robust answers in scenarios that may include unanswerable questions.
联合论坛报告筛选方式
每个会议由程序委员会推荐10篇共20篇论文,然后由联合论坛委员会共同筛选约10篇(每个会议5篇),并邀请作者在联合论坛做学术报告。
相关问题:
Q: 我是PRCV 2022会议论文作者,我需要怎么申请才能在联合论坛作报告?
A: 不需要申请,联合论坛委员会将会主动邀请优秀论文的作者参加。
Q: 我的PRCV 2022论文被选中,我需要在DICTA 2022会议上作报告吗?
A: 是的,你需要面向不同的听众做两场报告,一场在PRCV 2022会议期间,一场在DICTA 2022会议期间。
Q: 联合论坛是线上还是线下方式举办?
A: 拟采用线上线下结合方式。考虑到疫情带来的旅行不便,报告人可以根据情况选择线上或者线下参加,听众也会以两种方式参加。
Q: 如果被选中,报告语言是中文还是英文?
A: 为方便国际交流,报告语言及所有材料应用英文来表达。
Q: 如果我的PRCV 2022论文被选中,我需要注册DICTA 2022会议吗?
A: 是的。但DICTA 2022会豁免您的注册费。
Q: 如果我的PRCV 2022论文被选中,我的论文会出现在DICTA 2022论文集中吗?
A: 不会。您的论文只会在PRCV 2022论文集中,不会出现在DICTA 2022论文集中。
